BECAUSE MEMORY MATTERS
Market map: Exploring the future of memory-centric computing and its implications for the startup ecosystem
Lise Rechsteiner, Maximilian Odendahl, Jakob Lingg, Patrick Tucci*
A new computing era?
The volume of data created, captured, copied, and consumed globally has significantly increased in recent years. This increase can be partly attributed to the growing number of internet users and the proliferation of sensors and interconnected devices. This abundance of data powers various applications in multiple domains, with machine-learning applications currently leading the way. However, one of the challenges lies in efficiently handling the enormous volume of data available, in terms of both time and energy consumption.
One approach to addressing these computational challenges associated with data involves transitioning from conventional computing systems and accelerators to near-memory computing (CNM) and in-memory computing (CIM) architectures. Recently, both CNM and CIM architectures have been prototyped and commercialized. To understand the developments in this field, we teamed up with Jeronimo Castillon and his team at the Chair for Compiler Construction at TU Dresden. They conducted a survey on the current Compute-near-memory and Compute-in-memory landscape, a report of which can be found at: https://arxiv.org/abs/2401.14428.
Here, we will briefly summarize the main findings and introduce the fundamentals of CNM and CIM architectures. If you’re a startup active in this field and want to be mentioned in the updated version of the market map, please get in touch!
The bottlenecks in Von Neumann computing architectures
Most computing systems today are based on the Von Neumann paradigm. In this paradigm the processor and the memory are two separate entities, connected by buses. Typically, the central processing unit (CPU) retrieves data from memory via the buses, carries out the necessary calculations, and then stores the results back to memory. This data transfer between the processing unit and memory often poses a bottleneck for data-intensive tasks. This is mainly due to limitations on transfer rates and the significant energy requirements per bit of the buses, with the data movement alone often accounting for the largest proportion of the total energy consumed in computing systems.
These performance constraints are particularly noticeable in data-intensive applications, like Deep Neural Networks (DNNs). In DNNs, weights are stored in memory and retrieved layer by layer during computation. This may require transferring several hundred gigabytes of data between the memory and processor through a narrow channel, significantly bottlenecking system performance.
A solution to overcome the limitations of transfer rates is to minimize data transfer on the bus by moving a significant proportion of computations closer to the data (memory). This involves shifting from a CPU-centric design to a memory-centric design. The role of the CPU transitions from being responsible for all computations, to issuing commands and managing computations that cannot be efficiently executed close to memory.
Understanding Compute-in-memory and Compute-near-memory
Compute-in-memory (CIM), also known as processing-using-memory, and compute-near-memory (CNM), also known as processing-near-memory, are two prominent classes of memory-centric computing paradigms.
In CNM systems, as the name implies, computation takes place closer to the memory, reducing the distance that data has to travel. However, computations still occur outside the memory and are facilitated by a dedicated logic unit connected to the memory module via a high-bandwidth channel.
Compute-in-memory (CIM) systems, in turn, execute computations directly within the memory device, eliminating data movement almost completely. This computation can be further divided into two categories. First, computation occurs within the memory cells in the memory array, known as CIM-array (CIM-A). Second, computation takes place in the memory peripheral circuitry, known as CIM-peripheral (CIM-P). Both approaches leverage the inherent physical properties of the memory components, like Kirchhoff’s law for analog dot-products in crossbars.
A high-level overview of these systems can be seen in Figure 1.
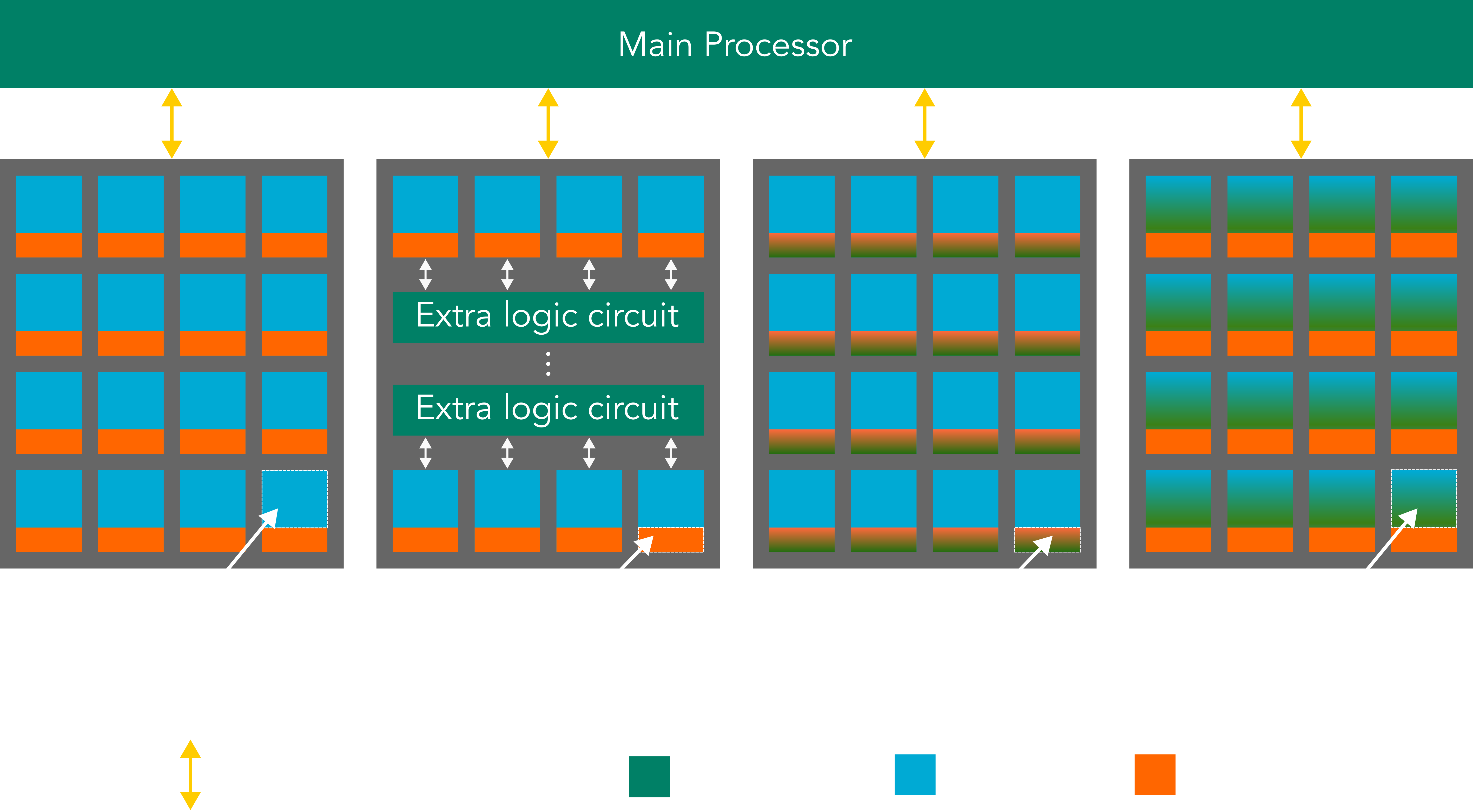
Figure 1: Overview of computation systems, showing where computation is performed a) COM: outside of memory system, b) CNM: logic connected to the memory via high-bandwidth channel, c) CIM-P: in the memory peripheral circuitry, and d) CIM-A: using memory cells within the memory array. Adapted from [1].
The CIM/CNM landscape report provides a comprehensive comparison of prominent volatile and nonvolatile memory technologies, including static random-access memory (SRAM), dynamic random-access memory (DRAM), phase change memory (PCM), magnetic RAM (MRAM), and resistive RAM (RRAM). The report includes examples of CIM and CNM architectures based on these technologies, commercial and academic, and compares performance, reliability, power usage, and other relevant metrics. Additionally, it reports on current programming models, systems integration, and demonstrated benefits. At present, no memory device can optimize all key metrics. However, the distinct characteristics of the different memory devices creates the opportunity to utilize them for different application areas to achieve optimal results.
Why now?
Recently, there’s been a growing interest in CIM and CNM. This trend is driven by the convergence of two critical factors, with their timing being of paramount importance. First, the state of technological readiness has reached a point where these systems have moved beyond their prototypical stages and successfully entered the market. Second, the volume and usage of data in applications such as AI have greatly increased, reaching a critical size that poses unprecedented challenges to traditional computing architectures.
An example of this limitation can be seen in smartphones. Modern devices come with a wide range of machine-learning algorithms that enable multiple smart applications, ranging from camera improvements, to facial recognition or battery optimization solutions. However, as the number of models increases, and many need to run concurrently, the transfer between memory and CPU intensifies as a bottleneck. Additionally, there are physical space constraints on the circuit boards and power consumption considerations for computing operations.
Importantly, this problem is not exclusive to smartphones; it is a challenge that extends to various consumer electronic devices and beyond.
This shift is particularly relevant in the context of recent advances in AI, such as large-language models exemplified by OpenAI’s ChatGPT. These applications process colossal data sets and demand considerable computational power. The training of ChatGPT itself required a formidable array of hardware, including over 3,600 NVIDIA servers and approximately 29,000 GPUs [2], underscoring the intense energy requirements of such endeavors. Forecasts suggest that by 2027, AI model training could account for as much as 0.5% of worldwide electricity usage.
In light of these figures, cost and environmental sustainability have become important considerations, prompting industry giants like Microsoft to explore alternative, more sustainable energy sources for their data centers [3]. Alternatively, transitioning from the conventional Von Neumann model to a new architecture type could address those increasing energy requirements.
Challenges & Evolving Startup Landscape
While CIM and CNM systems are continuously evolving and being researched, their market penetration is still limited. Beyond the clear constraint of hardware being in its early stages, this limitation is due to the absence of robust software development systems, impacting programmability and optimization. Furthermore, the reliability of non-volatile memory, which can become essential for future CIM systems, requires the development of performance models and tools for profiling and analysis. Additionally, there is a lack of tools available for exploring design spaces of CIM and CNM systems at various levels, including device, circuit, and architecture.
Numerous companies, including both established incumbents and startups, many of which have only recently entered the field, are working in the CIM and CNM market to help overcome the obstacles mentioned above and address the limitations of contemporary computing. These solutions have a wide range of applications, from edge computing to high-performance data centers, demonstrating their versatility and potential impact in multiple domains. At present, they are predominantly based on SRAM technology, although solutions based on non-volatile resistive and flash technologies are on the horizon. The transition to energy-efficient NVM-based CIM systems is projected to take some time as there are significant challenges such as reliability, drifting, yield, and integration problems that must be addressed beforehand.
An overview of start-ups present in the market is shown in Figure 2. The report also details the products, technologies, and funding status of those companies. Please note that this compilation is not exhaustive and based on publicly available information at time of publication; it includes only companies known to us and those that, based on our understanding, fall within the CIM and CNM categories. While extensive research went into the commercial landscape in the report, the field is quite dynamic and in constant change. We thus welcome additional input from the community that would help round up the overview.
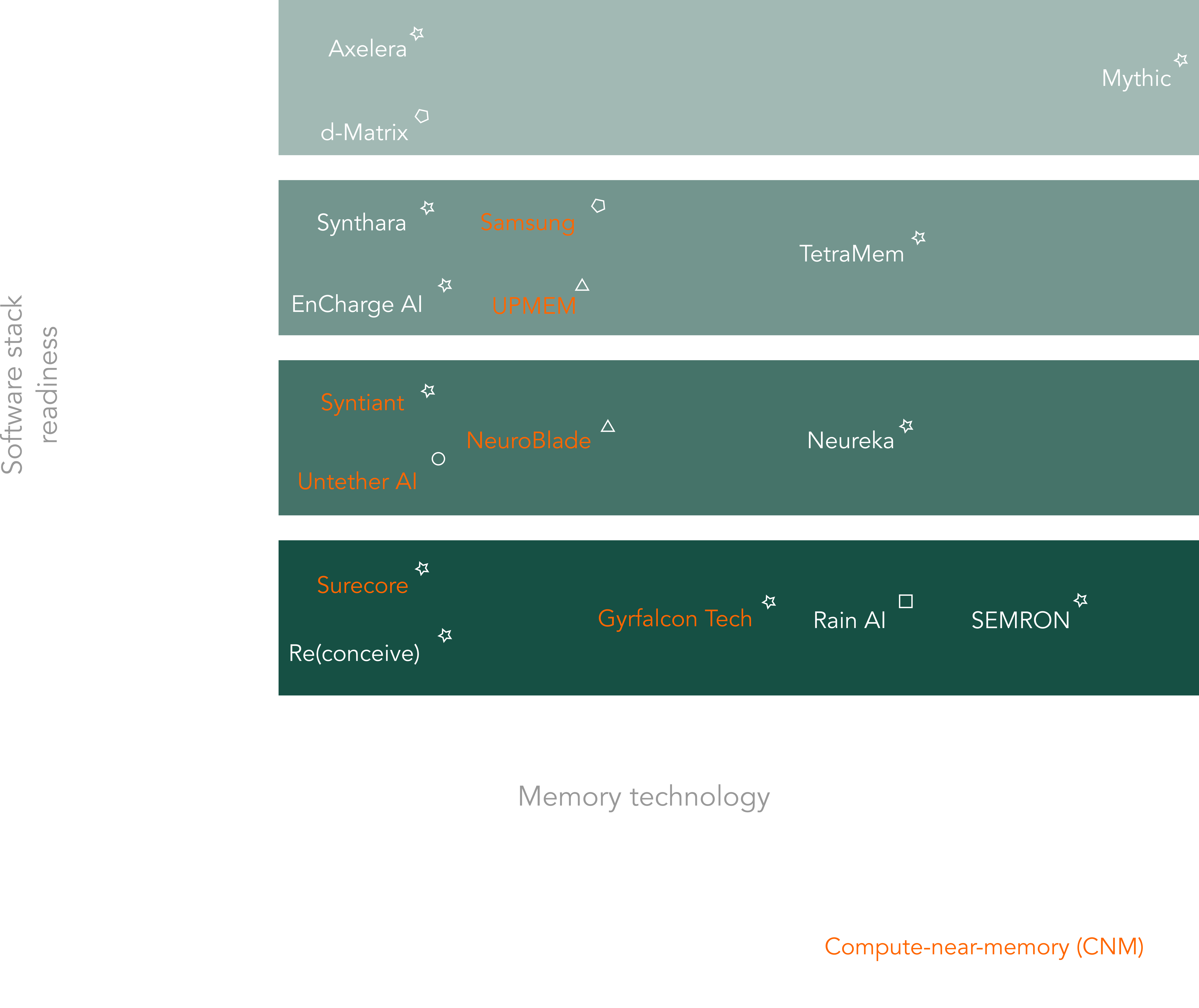
Figure 2: Landscape of CIM and CNM companies known to us, including their technologies, target applications and software stack readiness. Adapted from [1].
Closing remarks
The shift from traditional computing architectures to enhanced throughput and energy-efficient models like CIM and CNM is poised to shape the future of computing. While still evolving, initial applications in CIM and CNM have shown promising potential, indicating a significant shift in how we approach data processing and efficiency.
The average technological maturity in this field is robust, characterized by diverse approaches that are nearing market tipping points. The challenges within this domain are well-defined, fostering a burgeoning ecosystem that offers opportunities along the entire value chain. This scenario signals a ripe opportunity for deep tech investors.
The convergence of technological readiness and market potential makes this an exciting time for investors and entrepreneurs looking to contribute to and benefit from the next wave of computing advancements.
Stay tuned to find out how we applied our learnings!
– – – –
[1] Asif Ali Khan, João Paulo C. De Lima, Hamid Farzaneh, & Jeronimo Castrillon. (2024). The Landscape of Compute-near-memory and Compute-in-memory: A Research and Commercial Overview. https://doi.org/10.48550/arXiv.2401.14428
[2] Alex de Vries (2023). The growing energy footprint of artificial intelligence. Joule, 7(10), 2191-2194. https://doi.org/10.1016/j.joule.2023.09.004
[3] J. Calma (2023). Microsoft is going nuclear to power its AI ambitions. The Verge. https://www.theverge.com/2023/9/26/23889956/microsoft-next-generation-nuclear-energy-smr-job-hiring